Revue des algorithmes de recommandation
On peut discerner cinq grandes familles d’algorithmes :
1/ Les filtrages collaboratifs
Le principe consiste à utiliser les opinions et évaluations d’un groupe pour aider l’individu. Une fois cette connaissance acquise on peut s’en servir soit pour découvrir des produits semblables parce qu’ils plaisent aux même personnes, ou bien des individus similaires parce qu’ils aiment les mêmes choses, c’est ainsi que fonctionnent les systèmes des sites de rencontre par exemple.
Les systèmes de filtrages collaboratifs fonctionnent généralement en résolvant des problèmes de prédiction, qui sont résolus en reconstruisant la matrice utilisateur/produit en appliquant des méthodes de factorisations matricielles (SVD, NMF, …).
Il existe deux sous-catégories d’algorithmes de filtrage collaboratifs :
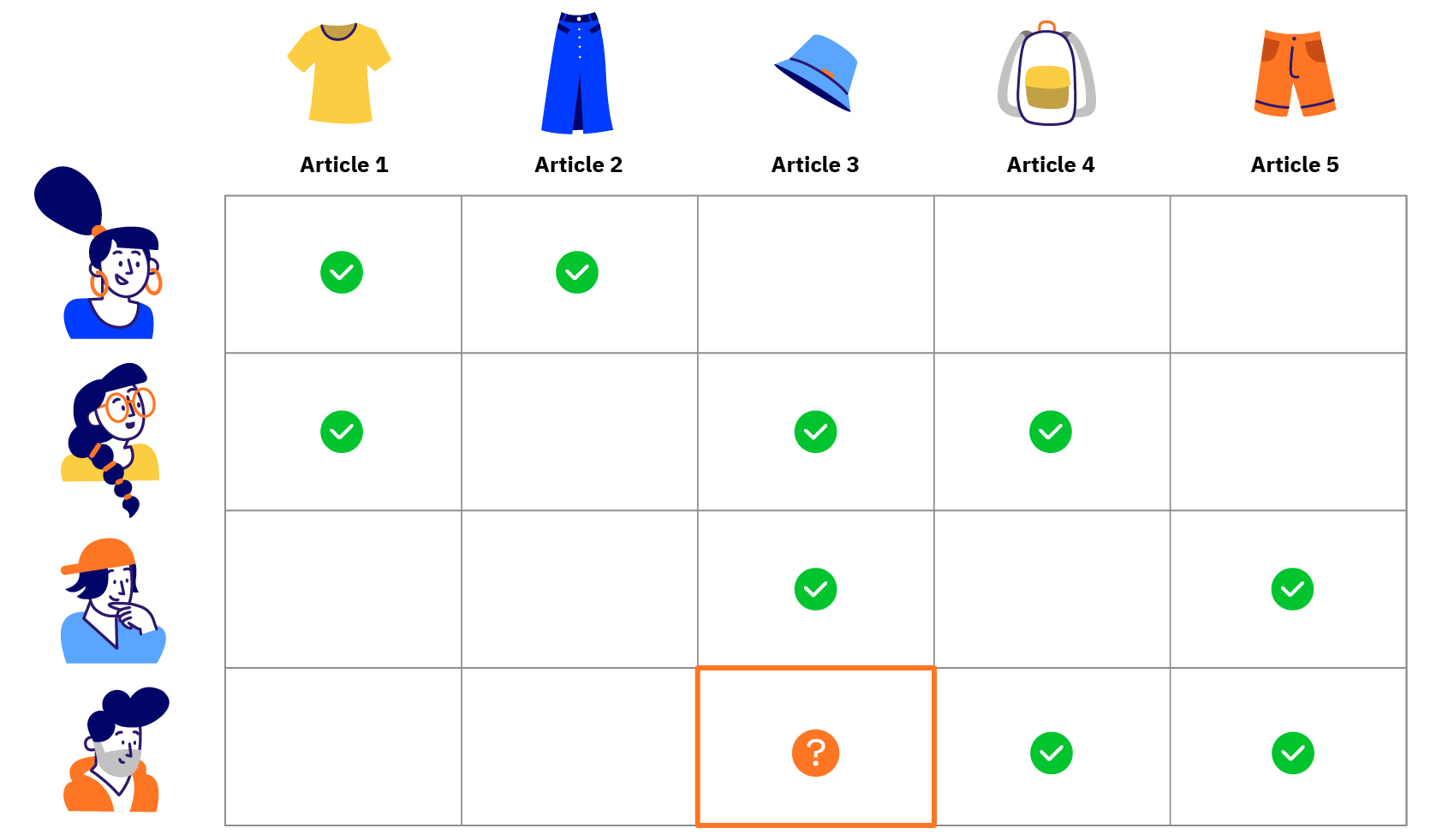
- Les méthodes centrées utilisateurs, qui recommandent sur la base des liens entre les individus : si Pierre et Paul donnent généralement des notes voisines aux mêmes films, alors si Paul n’a pas vu un film auquel Pierre a donné une bonne note, on va le lui recommander et réciproquement. Pour déterminer le degré de proximité entre Pierre et Paul, et déterminer s’il est préférable de recommander à Paul à partir des choix de Pierre plutôt que ceux de Jacques, on peut utiliser des mesures appelées « coefficients de corrélation » (on peut utiliser le coefficient de corrélation linéaire de Pearson, qui n’est rien d’autre que le cosinus, ou encore le coefficient de Spearman ou celui de Jaccard).
- Les méthodes centrées items, qui vont plutôt se baser sur les similarités de goût inspirés par les objets : si Le Grand Meaulnes et L’Homme pressé sont deux romans qui ont été appréciés par les mêmes lecteurs et qu’on sait que Jean a aimé Le Grand Meaulnes, on va lui recommander l’Homme pressé.
2/ La recommandation centrée sur les contenus
Dans ce cas, le système n’utilise pas les goûts des autres utilisateurs, il se contente d’exploiter les attributs des produits pour effectuer des mesures de similarité avec les objets dont on est sûr qu’ils sont appréciés par l’utilisateur.
Plusieurs types de caractéristiques peuvent être utilisées : nous avons par exemple utilisé le texte pour nos systèmes de recommandation d’articles scientifiques pour le groupe pharmaceutique Servier, pour la recommandation de programmes TV pour le groupe Prisma Media, ou encore de la recommandation de petites annonces à grande échelle. Des images peuvent aussi être utilisées comme nous l’avons fait pour du criblage à haut débit qui consiste à recommander des molécules qui présentent un intérêt éventuel pour des applications pharmaceutiques.
3/ Les systèmes basés sur les personnes/La recommandation centrée sur les utilisateurs
À l’instar du système précédent, on n’exploite pas les liens entre individus mais les caractéristiques des individus. Parfois on ne s’intéresse qu’à des informations très générales : l’âge, le genre, la nationalité, … On parle alors d’algorithme démographique. Mais on peut aussi s’intéresser à des informations plus complexes, étudiant le comportement de l’utilisateur sur une application par exemple.
4/ Les systèmes basés sur des règles/Les systèmes de recommandation à base de règles
C’est une manière plus simple de fonctionner qui produit une recommandation à partir de filtres qui s’appuient sur des règles empiriques, théoriques ou intuitives élaborées par les expertises propres à l’entreprise mettant en place la recommandation.
Le moteur de recommandation que nous avons mis en production pour un site de recommandations de film repose en partie sur une expertise métier à base de règles. Ce type de système est particulièrement utile en cas de « démarrage à froid », c’est-à-dire quand nous n’avons pas encore suffisamment de données pour que les autres approches soient plus pertinentes. C’était le cas lors du lancement de la plateforme, puisqu’aucun utilisateur n’existait.
5/ Les méthodes de recommandation hybrides et ensemblistes.
En pratique et comme souvent, les choix sont rarement tout à fait tranchés entre ces quatre grandes familles de systèmes. On choisit en général une hybridation de ces méthodes. Les systèmes démographiques, par exemple, donnent des résultats douteux lorsqu’ils sont utilisés seuls mais s’avèrent d’un réel intérêt quand ils sont alliés à d’autres algorithmes.
Par ailleurs, comme les systèmes de même nature sont généralement incapables individuellement d’atteindre tous les objectifs évoqués précédemment, on les assemble pour améliorer la satisfaction. C’est finalement là que réside le secret des performances des systèmes de recommandation que nous côtoyons au quotidien : ils multiplient les approches pour en restituer une synthèse efficace.
Seulement voilà, dire qu’on va mélanger les méthodes ne suffit pas. Encore faut-il savoir comment. Voici quelques façons de faire :
- par pondération : on pondère les scores obtenus par différents algorithmes et on les somme pour n’en obtenir qu’un seul et ensuite donner les résultats. C’est pour ce type de système que nous avions opté pour le moteur de recommandation de Kombini ;
- par changement d’algorithme selon les périodes, les utilisateurs, les produits de manière à gérer efficacement les éléments de contexte
- en cascade : on effectue une première recommandation très large dont les résultats vont être les entrées du prochain système, et ainsi de suite.
- par initialisations successives : cette fois, c’est le modèle produit par un système qui est ré-utilisé pour initialiser le modèle qui sera produit par le système suivant (au lieu que cela ne soit fait au hasard)
- par mélange : on peut aussi tout simplement mixer des recommandations produites par différents systèmes.
Amazon, un cas typique de recommandation hybride
Si une entreprise a très rapidement compris l’intérêt des systèmes de recommandation c’est bien Amazon. Les recommandations sont à la fois basées sur les caractéristiques des articles (système orienté contenu), sur le comportement des clients (système orienté utilisateur) et sur le comportement des autres individus. On peut lire sur la plateforme par exemple : « 90 % des utilisateurs qui ont acheté ce jean, ont acheté une de ces paires de basket », assertion dans laquelle on est maintenant à même de reconnaître un filtrage collaboratif orienté objet.