-
Kernix Lab,
-
Data scientist
Publié le 02/04/2014
Quel est le lien entre Walt Disney et Louix XIV ? Ou entre Vladimir Poutine et le Dalaï-Lama ?
Peut-être avez-vous vu passer sur vos flux Twitter, Facebook ou Google+ durant ces derniers jours des questions de ce genre. Si ce n’est pas le cas, il est encore temps d’aller découvrir la dernière création du Kernix Lab : Wikidistrict.
Wikidistrict est un projet de longue haleine, qui nous permet de démontrer la maturité technique des technologies autour du graphe, ainsi que la pertinence de ce modèle de données pour des tâches complexes d’extraction d’informations, notamment en ce qui concerne la découverte d’informations inédites. Le projet s’est naturellement imposé à nous de par la nature de Wikipédia.
L’encyclopédie collaborative est devenue ces dernières années une référence sur internet. Son approche innovante du partage et de la dissémination du savoir à l’échelle mondiale en a fait un projet unique et inimitable à bien des égards.
Elle constitue également une source de données incroyablement riche. Elle est régulièrement citée dans les listes des jeux de données de références lorsqu’il s’agit de tester une solution d’analyse sémantique, de traitement du langage, ou d’autres algorithmes orientés big data.
Enfin, c’est un exemple parfait de réseau de données, tissé par les liens qui joignent l’ensemble des pages. Google le premier, a montré la puissance du graphe dans la modélisation de grands volumes de données. PageRank, l’indicateur historique de la pertinence des sites internet dans le moteur de recherche, se concentre principalement sur l’information déduite à partir des relations et non dans le contenu des pages. Avec Wikidistrict, nous souhaitons aborder l’exploration de l’encyclopédie sous un angle différent, en suivant les plus courts chemins entre les pages.
Fidèles à leur adhésion à la philosophie de l’open data, les données Wikipédia sont accessibles à tous, dans des formats standards facilement exploitables à l’adresse dédiée.
Nous avons donc récupéré les derniers dumps de la base de données, qui ont lieu de façon régulière, une fois par mois. Ils nous permettent d’avoir accès à l’ensemble des pages ainsi qu’aux différents liens qui les relient. Le travail a été fait sur la version anglaise, pour un certain nombre de raisons, la principale étant que le volume des données est largement supérieur aux versions des autres langues, à cause notamment de son rayonnement international, et du plus grand nombre de contributeurs dans cette langue.
Le schéma complet de la base est disponible ici :
http://upload.wikimedia.org/wikipedia/commons/4/41/Mediawiki-database-schema.png
On y trouve différentes tables qui contiennent d’une part la structure en graphe, notamment les tables « pages », « pagelinks », « redirect », ainsi que des métadonnées supplémentaires.
Il faut noter que l’import des dumps est particulièrement long (plusieurs heures). Après un ensemble de processus de nettoyage et de mise en forme, les données sont importées au sein d’un graphe. Nous avons choisi d’utiliser la base de graphe neo4j, de notre partenaire Neotechnology.
Un travail d’étude en amont a été fait sur la pertinence des données, afin d’éviter d’alourdir inutilement le graphe par du bruit ou de l’information redondante, les deux grandes plaies du Big Data.
On trouve par exemple plusieurs pages de redirections, c’est-à-dire des pages avec des noms différents, qui redirigent automatiquement vers la même page de contenu. Nous avons court-circuité l’ensemble des redirections dans le graphe, afin de ne garder que les liens directs.
Nous avons nettoyé également des pages qui ne correspondent pas à du vrai contenu, comme les pages homonymes entre autres, qui créent des relations peu pertinentes au sein du graphe. Nous avons supprimé toutes celles qui étaient marquées comme telles dans la catégorie correspondante (« disambiguation pages »).
On observe au final une différence flagrante entre le volume initial de données, et le volume d’informations utiles. On passe ainsi, sur les dumps du mois de mars 2014, de 10,248,859 de pages potentielles à 4,296,367 de pages réelles, et de 459,456,746 de relations à 318,875,034 de liens directs.
On note donc que moins de la moitié des pages, et seulement 70% des relations, contiennent effectivement de l’information.
Wikidistrict calcule en temps réel le chemin le plus court entre 2 pages. La profondeur du chemin peut être vue comme le nombre minimal de clics à la souris qui permet d’atteindre la page cible depuis la page de départ. Ce chemin n’est pas unique, et le nombre grimpe très vite avec la profondeur, du fait de l’ensemble des combinaisons possibles. Et bien entendu, ce chemin n’a aucune raison d’être symétrique.
Une recherche de chemin basique montre très vite des limites quant à la pertinence. Certains types de pages ont en effet tendance à être « trop » connectées, et une grande part de chemins les traverse.
L’exemple flagrant concerne les pages de nature géographique, comme les pays et les grandes métropoles. Elles contiennent parfois jusqu’à plusieurs dizaines, voire centaines de milliers de liens entrants (plus de 188000 pour la page France pour un peu plus de 1800 liens sortants, et 576000 pour les USA contre 1400 liens sortants). Leur probabilité d’apparition dans un chemin est particulièrement élevée par rapport aux autres pages, et elles ont effectivement tendance à revenir de façon systématique. Afin d’y remédier, nous avons développé une méthode de pondération qui permet de pénaliser les chemins avec ce genre de pages.
Cette méthode nous permet également de pénaliser un autre type de pages aux caractéristiques induisant du bruit : les listes. On n’en soupçonne pas le nombre incroyable, mais il y en a pour tous les goûts. Ces pages sont l’exact opposé en termes de caractéristiques, puisqu’elles comptent un grand nombre de liens sortants.
Contrairement au cas d’homonymie évoqué plus haut, qui créé des chemins dont on peut être sûr de l’absence de pertinence, ce genre de pages peuvent parfaitement être justifiées sur certains chemins. C’est pourquoi nous avons préféré les conserver. Il a fallu en revanche trouver un subtil équilibre afin de les pénaliser suffisamment pour qu’elles ne soient pas envahissantes, tout en leur laissant une chance d’apparaître lorsqu’elles font sens.
Malgré la complexité des calculs, nous sommes fiers d’avoir réussi le pari du temps-réel (une première mondiale à notre connaissance). La figure suivante montre la répartition des temps de calcul des chemins. Près de 85% des chemins (depuis le lancement du service) ont été calculés en moins d’une seconde, et près de la moitié sont en dessous du dixième de seconde. Comme on peut s’y attendre, on constate sur le graphique que le temps s’allonge avec la profondeur.
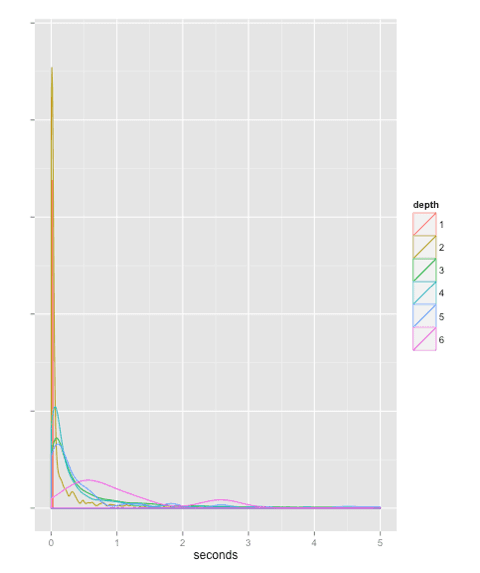
Nous donnons également à titre indicatif la distribution relative de la profondeur des chemins, sur les 8000 derniers chemins recherchés depuis Wikidistrict. Il est à noter que cette distribution peut être biaisée par le type de recherche auquel pensent spontanément les utilisateurs du service, et n’est pas nécessairement une représentation fidèle de la distribution réelle de la profondeur des chemins (les requêtes tendent à privilégier des personnalités, des lieux, des événements, …), même si on peut supposer qu’elle s’en approche.
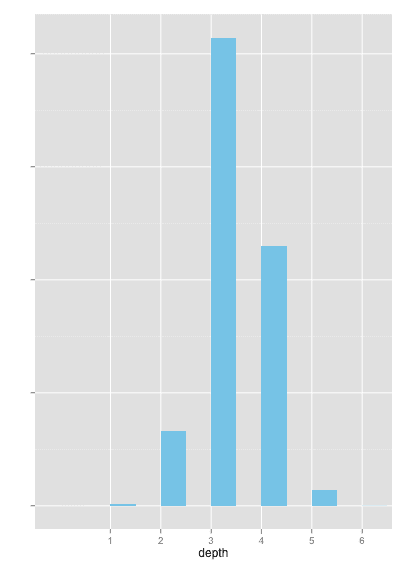
Les plus observateurs auront certainement noté que la profondeur maximale actuelle est de 6. Ce n’est pas une limitation de notre part, et la question reste encore ouverte de savoir si un chemin de profondeur 7 existe !
A terme, nous envisageons plusieurs axes d’améliorations, et le Kernix Lab travaille d’arrache-pied pour les rendre disponibles le plus vite possible, afin de faire la démonstration de la puissance des graphes, ainsi que de l’expertise de nos équipes.
N’hésitez pas à vous inscrire à notre newsletter pour être tenu au courant des dernières avancées.
