Cette conférence a permis de présenter nos travaux sur la classification de contenu textuel. Si nous pouvons lire régulièrement des articles sur la classification, ils ont souvent tendance à s’attarder sur le traitement des images. L’actualité estivale nous l’a encore montré avec la « révélation » lors d’une panne Facebook de l’étiquetage automatique des photos publiées sur le réseau social. Cet évènement était donc pour nous l’opportunité de présenter nos travaux sur une source omniprésente mais pourtant moins mise en lumière : le contenu textuel.
C’était également l’occasion d’avoir un aperçu des méthodes récentes appliquées à d’autres domaines et d’échanger avec d’autres chercheurs sur diverses problématiques que nous pouvons rencontrer dans nos projets data.
Nous présentons ici les différentes tendances de ce champ de la data science abordées lors de ces rencontres, et ce en partant du matériau de base que nous manipulons au quotidien, les données, classées selon leurs typologies.
Données textuelles
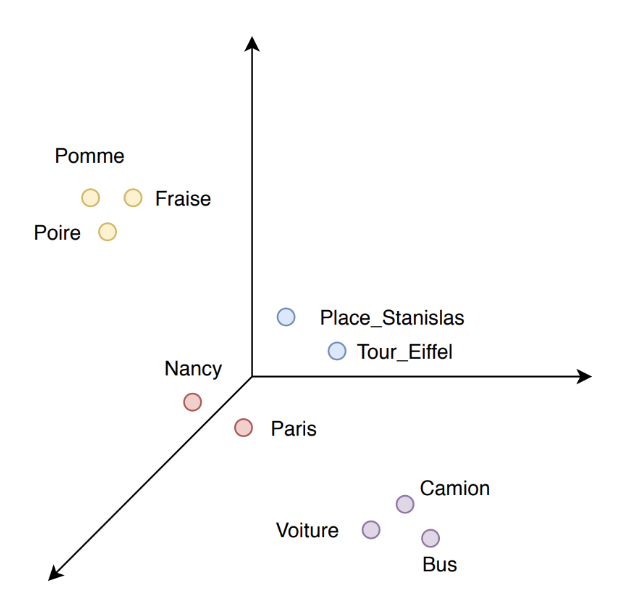
Notre contribution à cette conférence portait sur de la classification de données textuelles via des méthodes d’apprentissage par transfert. Plus précisément, nos travaux consistaient à l’évaluation de méthodes pour la substitution de word embeddings : les word embeddings permettent d’encoder la sémantique des mots dans des vecteurs (Figure 1).
Figure 1 : word embeddings.
Ces vecteurs peuvent alors significativement améliorer la classification de textes ou être utilisés en information supplémentaire pour d’autres objectifs de traitement du langage naturel (traduction automatique, détection d’entités nommés, etc.).
Cependant, pour des données spécialisées, certains mots sont inconnus du modèle de word embeddings. Ce type de modèle est fréquemment entraîné sur des sources offrant un grand volume de contenus pour couvrir un large panel sémantique mais qui présente l’inconvénient d’employer un langage grand public ou généraliste qui permet d’extraire le sens des mots (ex. : recours aux articles de Wikipédia). Si un modèle est entraîné avec les articles de Wikipédia, il pourrait rencontrer des difficultés à manipuler de nouveaux contenus qui ont recours à un lexique plus technique. Un exemple fréquent concerne le domaine de la santé. Il est vraisemblable que Wikipédia ne fournisse pas un panel large de noms de biomolécules.
Pour palier ces contraintes, il est fréquent de recourir à des méthodes de substitution. Une étude rigoureuse de ces méthodes de substitution est donc nécessaire et a donc été présentée et discutée lors de ces rencontres.
Ce type d’information sémantique de mots, encodés par des vecteurs, a été utilisé dans les travaux de Mickael Febrissy et. al. pour de la factorisation matricielle non-négative. Cette méthode a permis de faire de la classification non supervisée d’articles.
On parle de classification non supervisée quand aucun exemple explicite d’association entre un texte et une catégorie n’est donné à l’algorithme de classification en guise d’exemple d’apprentissage. L’algorithme trouve donc des groupes cohérents d’articles uniquement sur la base de leurs contenus respectifs. L’objectif est de faire émerger des textes des catégories sans le biais d’une grille de lecture préalablement établie.
On peut aisément envisager l’usage de cette méthode chez des producteurs ou diffuseurs de contenus. L’algorithme est ainsi capable de regrouper des articles en fonction de leurs thématiques. Imaginons une publication dédiée au sport, l’algorithme serait en mesure de classer les contenus concernant des sports de balles dans une catégorie et les sports mécaniques dans une autre.
Une alternative à la représentation vectorielle de mots pour encoder de l’information sémantique est d’utiliser des bases de données sémantiques. Une démonstration nous en a été faite par Jocelyn Poncelet qui a pu l’appliquer au domaine biomédical. Il a mis en lumière la possibilité d’appliquer des méthodes de partitionnement aussi bien sur des données biomédicales que sur des données de comportements de consommation dans des supermarchés.
La portabilité de la méthode d’un champ et d’un type de données à un autre offre des perspectives d’application concrète pour les entreprises que nous accompagnons.
Cas d’usage : L’analyse des verbatims
Lors d’une enquête de satisfaction ou d’un sondage, le traitement des retours fournis sur des questions ouvertes peut s’avérer complexe, chronophage et coûteux. L’emploi de l’IA avec un algorithme non supervisé, permet non seulement de faire émerger des groupements sans biaiser l’étude mais également d’envisager de réemployer le modèle sans nécessité de le réentrainer pour s’adapter aux spécificités des données d’entrée.
Données transactionnelles: vers plus de lisibilité
L’analyse de comportement est souvent tirée de données transactionnelles. C’est une pratique courante dans l’e-commerce pour optimiser l’efficacité d’outil marketing comme l’emailing.
Un exemple fréquent de données transactionnelles exploitées nous vient du panier d’un consommateur : lorsqu’il valide une commande sur un site e-commerce ou passe à la caisse dans un magasin, l’achat est historisé pour conserver les informations des différents produits achetés ensemble. L’association entre le client et le panier n’est pas retenue afin de ne pas conserver de données personnelles.
Ce type de données a fait l’objet de nombreux exposés (voir en particulier les quatres présentations d’Alexandre Bazin, Tatiana Makhalova, Alexanddre Termier et Lamine Diop). Le contenu détaillé (articles associées aux présentations) est disponible dans les actes de la conférence.
Ces méthodes de fouille de motifs donnent des premiers jets de résultats qui peuvent être difficile à exploiter par les équipes en charges dans les différentes organisations (qu’il s’agisse des services marketing ou commerciaux) en raison de l’abondance de motifs émergents et du niveau d’informations additionnelles qu’ils portent.
Exemple :
Parmi les produits qui se retrouvent le plus souvent dans le panier des français, on retrouve les pâtes et le riz. Cette association à elle seule n’apporte que peu d’information additionnelle.
Une méthode alternative, ou complémentaire, est d’utiliser des algorithmes de biclustering : cette jonction entre deux communautés de recherche a été faite par les travaux portant sur de l’analyse de concepts formels par Nyoman Juniarta et. al. Plusieurs présentations ont porté sur les treillis, qui constituent le cœur de méthodes d’extraction de règles d’association.
Données multidimensionnelles : exploiter l’information des différentes vues
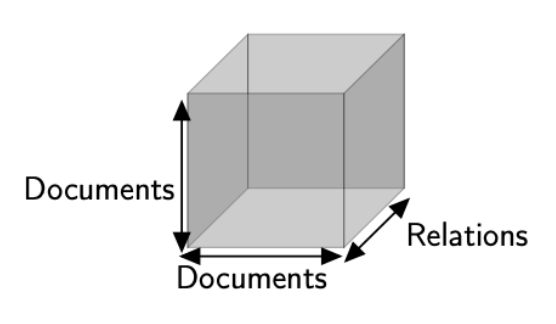
Les données multidimensionnelles sont présentes dans de nombreux domaines : on peut par exemple exprimer différentes relations d’un graphe à l’aide d’un tenseur 3d.
Exemple :
Cet article contient un lien vers la page d’accueil, et est également cité sur Twitter. Chaque ligne et chaque colonne représente une page web. Au croisement nous pourrons noter la présence d’un lien (0 ou 1). On peut alors multiplier ces tableaux en ajoutant une couche d’information spécifique (il s’agit d’un lien présent sur un réseau social, il s’agit du même nom de domaine…)
Ces tableaux différents sont alors assemblés pour constituer un tenseur 3d (Figure 2).
Figure 2 : Tenseur 3d pour représenter différents types de relations entre articles (crédits : Rafika Boutalbi).
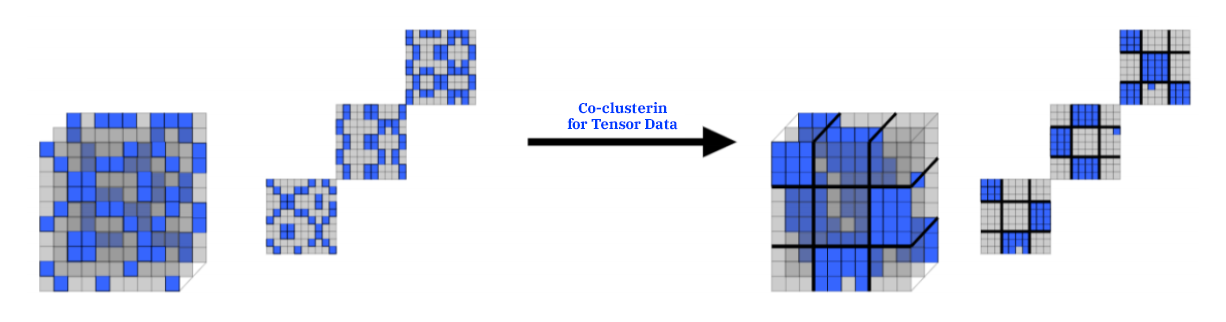
Rafika Boutalbi a présenté un modèle de classification croisée, permettant de classer deux dimensions simultanément. Ce type d’algorithmes appelé co-clustering a été par exemple implémenté dans le package Coclust auquel Kernix a contribué. Les travaux de Rafika Boutalbi constituent une extension au cas où plusieurs couches d’information sont disponibles (Figure 3).
Figure 3 : Classification croisée sur deux dimensions d’un tenseur 3d (crédits : Rafika Boutalbi).
Le partitionnement de données multidimensionnelles n’implique pas nécessairement de procéder à un partitionnement sur plusieurs dimensions. Par exemple, les travaux de Véronique Cariou portaient sur la classification de variables sur des données tridimensionnelles. Les travaux de Ndèye Niang sur des données multibloc concernaient la classification d’individus qui sont décrits par des variables structurées en blocs homogènes.
Séries temporelles : deux axes principaux de recherche
Les données issues de séries temporelles ont été utilisées dans deux travaux, se distinguant principalement par le type de classification voulu.
Milad Leyli-abadi a présenté une méthode pour détecter des changements communs à un ensemble de séquences catégorielles. En particulier une étude des données de consommation d’eau, collectées grâce aux compteurs intelligents Linky, a été menée. Le modèle incorpore de l’information météorologique et calendaire qui permet d’expliquer les changements de consommation de la population. Un autre cas d’usage est par exemple la prédiction de la fréquentation d’un musée en fonction de données calendaires et météorologiques. Ces travaux présentent une segmentation de périodes temporelles.
Les travaux présentés par Brieuc Conan-Guez s’attachent à un problème différent puisqu’il s’agit cette fois de partitionner des séries suivant leur forme. Ceci permet de regrouper dans une même classe des comportements similaires. Une étude comparant la méthode proposée par rapport aux méthodes plus connues « DTW Barycenter Averaging » et « K-Spectral Centroid » a été présentée.
Veille et partage
Cette seconde participation aux Rencontres de la Société Francophone de Classification nous a permis de discuter de différentes problématiques auxquelles nous sommes confrontés lors de la réalisation de projets data science. Nous avons retrouvé quelques confrères, avec qui par exemple nous avons réalisé un système de recommandation de petites annonces. Ces rencontres sont toujours enrichissantes car elles permettent de se tenir informé des dernières avancées en recherche dans le domaine de la data science. Elles permettent d’anticiper certaines difficultés et de s’inspirer de solutions trouvées dans différents domaines d’application.
Kernix aux XXVIe Rencontres de la Société Francophone de Classification